
Database sharding with Active Record
26th February 2019What is Database Sharding?
Database Sharding is a highly scalable approach for improving the throughput of large database-centric business applications. It is a type of database partitioning that separates very large databases into smaller, faster, easier-managed parts called data shards. Shard means “a small part of a whole”.
There are two ways of database partitioning: vertical and horizontal.
Vertical: “Involves creating tables with fewer columns and using additional tables to store the remaining columns. Normalization also involves this splitting of columns across tables, but vertical partitioning goes beyond that and partitions columns even when already normalized.”
Horizontal: “Involves putting different rows into different tables. For example, customers with ZIP codes less than 50000 are stored in CustomersEast, while customers with ZIP codes greater than or equal to 50000 are stored in CustomersWest. The two partition tables are then CustomersEast and CustomersWest, while a view with a union might be created over both of them to provide a complete view of all customers.”
Unlike horizontal partitioning, database sharding partitions the problematic tables in the same way, but it does this across potentially multiple instances of the schema. The obvious advantage would be that the database load for the large partitioned table can now be split across multiple either logical or physical servers and not just multiple indexes on the same logical server.
Reasons to implement database sharding.
- Scale application growth in database transactions and large volumes of data.
- Allow easier data migration
- Implement horizontal scalability for multi-tenant applications.
Why did I implement Database Sharding?
We needed an API where each client can access their database information. What does it mean? We have some enterprise clients and each client has its own database where they are saving all their information. There is an API that needs to consume that information but, as you can see, there are multiple database instances. After doing some research, I found that database sharding is a good approach for this case where the representation of each enterprise client is as a Company and each Company has its own information (database shard). LET’S DO IT!.
How to implement database sharding on Active Record.
First, take a look at the ar-octopus gem.
Octopus is a better way to do Database Sharding in ActiveRecord. Sharding allows using multiple databases in the same Rails application.
The API is designed to be as simple as possible. Octopus focuses on the end user by giving the power of multiple databases but with reliable code and flexibility. Octopus is compatible with Rails 4 and Rails 5.
Octopus supports:
- Sharding (with multiple shards, and grouped shards).
- Replication (Master/slave support, with multiple slaves).
- Moving data between shards with migrations.
There are two ways of declaring your databases shards in your application:
-
Declare your database instances inside of config/shards.yml
-
Dynamic shard configuration. Octopus allows us to set shards using ruby code.
Advantages of dynamic shard configuration:
- Configures the open connections on demand. NOTE: those connections will be handled by ActiveRecord connection pool.
- It is flexible to setup with Ruby code.
Setting Up
Install the gem in your Gemfile.
Gemfile
source 'https://rubygems.org'
git_source(:github) { |repo| "https://github.com/#{repo}.git" }
ruby '2.5.3'
gem 'rails', '~> 5.2.1'
gem 'pg', '>= 0.18', '< 2.0'
gem 'ar-octopus'
Add a migration to create Databases table to save shards information.
The API will have the databases credentials on its database and, in order to secure the information, I used this gem attr_encrypted to encrypt the credentials.
To generate the migration, run: *
bin/rails generate migration CreateDatabases
class CreateDatabases < ActiveRecord::Migration[5.2]
def change
create_table :databases do |t|
t.string :encrypted_host
t.string :encrypted_host_iv
t.string :encrypted_password
t.string :encrypted_password_iv
t.string :encrypted_username
t.string :encrypted_username_iv
t.string :encrypted_name
t.string :encrypted_name_iv
t.timestamps
end
end
end
We need to add the Database model and this is how it looks like:
app/models/database.rb
# frozen_string_literal: true
class Database < ApplicationRecord
attr_encrypted :username,
key: CredentialsReader.credentials[:api_token_encrypted]
attr_encrypted :name,
key: CredentialsReader.credentials[:api_token_encrypted]
attr_encrypted :password,
key: CredentialsReader.credentials[:api_token_encrypted]
attr_encrypted :host,
key: CredentialsReader.credentials[:api_token_encrypted]
end
On this table, we are going to have all our shards credentials. Then, when we need to create a new shard connection, we are going to fetch the credentials from here.
To save the company information we need to add the Company model:
app/models/company.rb
class Company < ApplicationRecord
has_one :database
validates :name, uniqueness: true
validates :name, presence: true
validates :api_token, presence: true
end
This table is going to have both the company name and a relationship with a database.
The service to create the shards configuration dynamically is the next:
# frozen_string_literal: true
module Databases
class ConnectionService
attr_reader :database, :company_name
def initialize(company)
@company_name = company.name
@database = company.database
end
def call
setup_database_connection unless shard_setup?
end
private
def shard_setup?
environment_config = Octopus.config[Rails.env.to_sym]
environment_config.present? && environment_config.key?(company_name)
end
def setup_database_connection
Octopus.setup do |config|
config.environments = [Rails.env.to_sym]
config.shards = {
company_name.downcase.to_sym => company_database_configs
}
end
rescue StandardError => exception
exception.message
end
def company_database_configs
{
adapter: 'postgresql',
database: database.name,
username: database.username,
password: database.password,
host: database.host,
encoding: 'unicode'
}
end
end
end
First, we need to pass the company object that is requesting information in the constructor and we are going to get their databases credentials. On the call method, we set up the connection in case it does not exist yet.
The connection has an identifier and, in this case, is the name of the company. With this identifier, we can ask for an existing connection or create a new one.
Now we can create our connection:
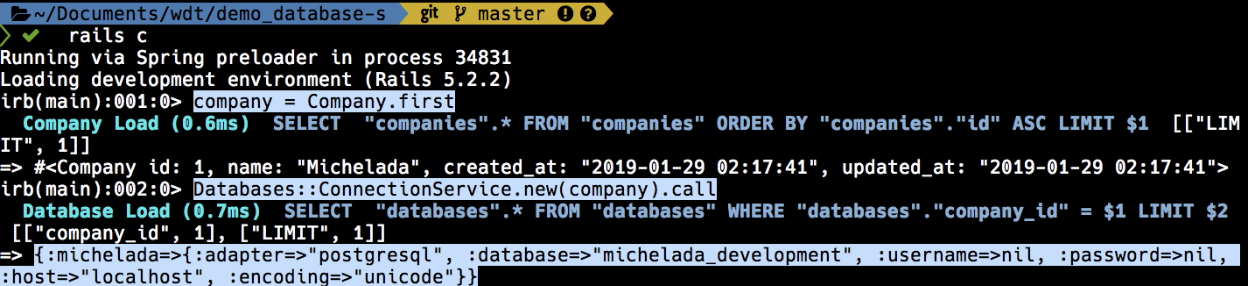
I previously added information to the Company table.
Now that we have the connection established, we can get the information that we want. In my case, I needed the Members information.
I added a Member model: this is important because ActiveRecord needs to manage that information through the model.
The member model class is next:
app/models/member.rb
class Member < ApplicationRecord
end
To access the correct shard, you need to use the established connection by the company key.

Now, we can create as many connections as we need and get information from different shards. In case you still do not have shards hosted on a server and you want to test it locally, there is a way to create more than one database in your Rails app.
In conclusion, database sharding is an option for horizontal scalability and Octopus is a complete, well-documented gem to implement database sharding.
View Comments