
GPU-Accelerated Computing with Ruby on Rails
25th August 2021
INTRODUCTION
These days, machine Learning is everywhere doing complex pattern recognition that would have taken a long time to code with traditional programming techniques. Ranging from performing face and speech recognition, restoring color from black and white photos, generating new images, doing lip reading at 95% accuracy, creating a scene from scratch and recognizing almost any pattern that you can think of.
GPU-Accelerated computing is here to stay and, for some algorithms, it is faster to run them in parallel than using the classic and reliable serial computation and, turns out that a lot of the algorithms used in AI benefits tremendously from parallel computing.
Although we've been working with computers that have several cores in a CPU for quite a while now, nothing compares to have thousands of such small computing cores as ants crunching numbers.

Contrast that with a classical CPU that only has 18 cores and can handle 36 threads at the time like the new Intel i9. Although terrific for fast serial workloads, and some parallelism, it would not stand up against a massive set of GPU'S working together.

I recently got my hands on a small computer that has some decent specs and is teaching me GPU programming. It has everything already set up for me, sort of like a plug and play device. I went to Amazon and got the Nvidia Jetson Nano: a totally affordable and quite powerful unit.

I started to learn the CUDA platform, which is designed to work with programming languages such as C, C++, and there are some Python wrappers for CUDA and runtime APIs. I kind of went low level and decided to use C since it feels more intuitive.
After I learned enough to be dangerous, I decided that it was time to use a framework that I love, Ruby on Rails, and have a wrapper for CUDA.
There are some outdated gems out there that I could use but I honestly wanted to do all the wiring by myself. The first step was to consult The Ruby C API and create an extension that I could load in ruby.
It turns out that it was easy to do, here is the minimal C code for creating a shared library that I named "nvidia.cu"
#include <stdio.h> #include <stdlib.h> #include <math.h> #include <assert.h> #include <cuda.h> #include <cuda_runtime.h> #include "ruby.h" __global__ void simple_kernel(float *CUDA_A, float *CUDA_C) { int tid = blockIdx.x * blockDim.x + threadIdx.x; CUDA_C[tid] = CUDA_A[tid] + 3; } int simple_vector(int v){ float A[3]= {2.0,4.0,6.0}; float *C; float j = (float) v; C = (float*)malloc(sizeof(float) * 512); A[0] =(float) v; printf("number_in -> %f\n",j); float *CUDA_A, *CUDA_C; cudaMalloc((void**)&CUDA_A, sizeof(float) * 4); cudaMalloc((void**)&CUDA_C, sizeof(float) * 4); cudaMemcpy(CUDA_A, A, sizeof(float)*4, cudaMemcpyHostToDevice); simple_kernel<<<1,4>>>(CUDA_A, CUDA_C); cudaMemcpy(C, CUDA_C, sizeof(float) * 4, cudaMemcpyDeviceToHost); printf("and_we_got-> %f\n",C[0]); printf("and_we_got-> %f\n",C[1]); printf("and_we_got-> %f\n",C[2]); printf("and_we_got-> %d\n",(int)(5.0*(C[0]+C[1]+C[2]))); return (5.0)*(C[0]+C[1]+C[2]); } static VALUE get_number_from_card(VALUE self, VALUE value) { Check_Type(value, T_FIXNUM); int number_in = NUM2INT(value); int number_out = simple_vector(number_in); return INT2NUM(number_out); } extern "C" void Init_nvidia() { rb_define_global_function("get_number_from_card", get_number_from_card, 1); }
Without going into too much detail, the code is pretty straightforward: Init_nvida() will be called when the code gets loaded in Ruby.
After that it will define a Ruby global function called "get_number_from_card" rb_define_global_function("get_number_from_card", get_number_from_card, 1);
Then get_number_from_card() in turn will call simple_vector() and that function will setup all the context for the GPU card and will invoke simple_kernel() this time that code will execute in parallel in the Nvidia card itself.
We will collect the result and return it back to Ruby.
For a complete guide of CUDA programing follow this link.
Now, let's compile a shared library that will be loaded in ruby, I'm using Ruby 2.7 and RVM.
$ nvcc -I$HOME/.rvm/rubies/ruby-2.7.0/include/ruby-2.7.0/ -I$HOME/.rvm/rubies/ruby-2.7.0/include/ruby-2.7.0/aarch64-linux --ptxas-options=-v --compiler-options '-fPIC' --shared nvidia.cu -L. -L$HOME/.rvm/rubies/ruby-2.7.0/lib -L$HOME/.rvm/rubies/ruby-2.7.0/lib -lruby -lm -lc -o nvidia.so
You will end up with two files.
$ ls -la /tmp/nvid* -rw-rw-r-- 1 unix unix 1304 ago 17 11:53 /tmp/nvidia.cu -rwxrwxr-x 1 unix unix 566944 ago 17 12:23 /tmp/nvidia.so
Now, fire up IRB and load the shared library nvidia.so
$ irb '$LOAD_PATH << "/tmp/" require 'nvidia' n = get_number_from_card(5) number_in -> 5.000000 and_we_got-> 8.000000 and_we_got-> 7.000000 and_we_got-> 9.000000 and_we_got-> 120 puts n 120
And that's it from here the sky is the limit! You can use Ruby on Rails with ease now. I did a small Rails 6 application and, by using WebSockets, I was able to communicate with the CUDA card.
Here is the list of relevant files for a Rails App once you've created the basic Rails setup and do the wiring.
1. Generate a landing controller Pages
$ rails g controller pages index
2. Routes should look like this:
config/routes.rb
Rails.application.routes.draw do root 'pages#index' get 'pages/index' end
3. Generate an ActionCable WebSocket Channel
$ rails g channel room
4. Edit the files and add the following lines.
app/channels/room_channel.rb
$LOAD_PATH << "/tmp" require 'nvidia' class RoomChannel < ApplicationCable::Channel def subscribed stream_from "room_channel" end def unsubscribed # Any cleanup needed when channel is unsubscribed end def receive(data) puts "RECEIVE BY BROWSER #{data['receive']}" n = get_number_from_card(data['receive'].to_i) puts "Nvidia card returned value #{n}" # Broadcast result back to the browser ActionCable.server.broadcast "room_channel", message: "Calculated Valued from the card was #{n}" end end
app/javascript/channels/room_channel.js
import consumer from "./consumer" let a = consumer.subscriptions.create("RoomChannel", { connected() { // Called when the subscription is ready for use on the server console.log("Connected to room channel") //consumer.send({message: 'This is a cool chat app.'}); }, disconnected() { // Called when the subscription has been terminated by the server }, received(data) { // Called when there's incoming data on the websocket for this channel console.log("Broadcast ${data}") } }); window.hola=a window.hola.received = function(data) {console.log(data)}
5. Let's fire up Rails and use the browser to communicate with the CUDA card.
$ bundle exec rails s -b 0.0.0.0 Puma starting in single mode... * Version 4.3.8 (ruby 2.7.0-p0), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stop
6. Open the Chrome browser and see in the console how I'm sending messages to the heart of the CUDA card and getting results back.
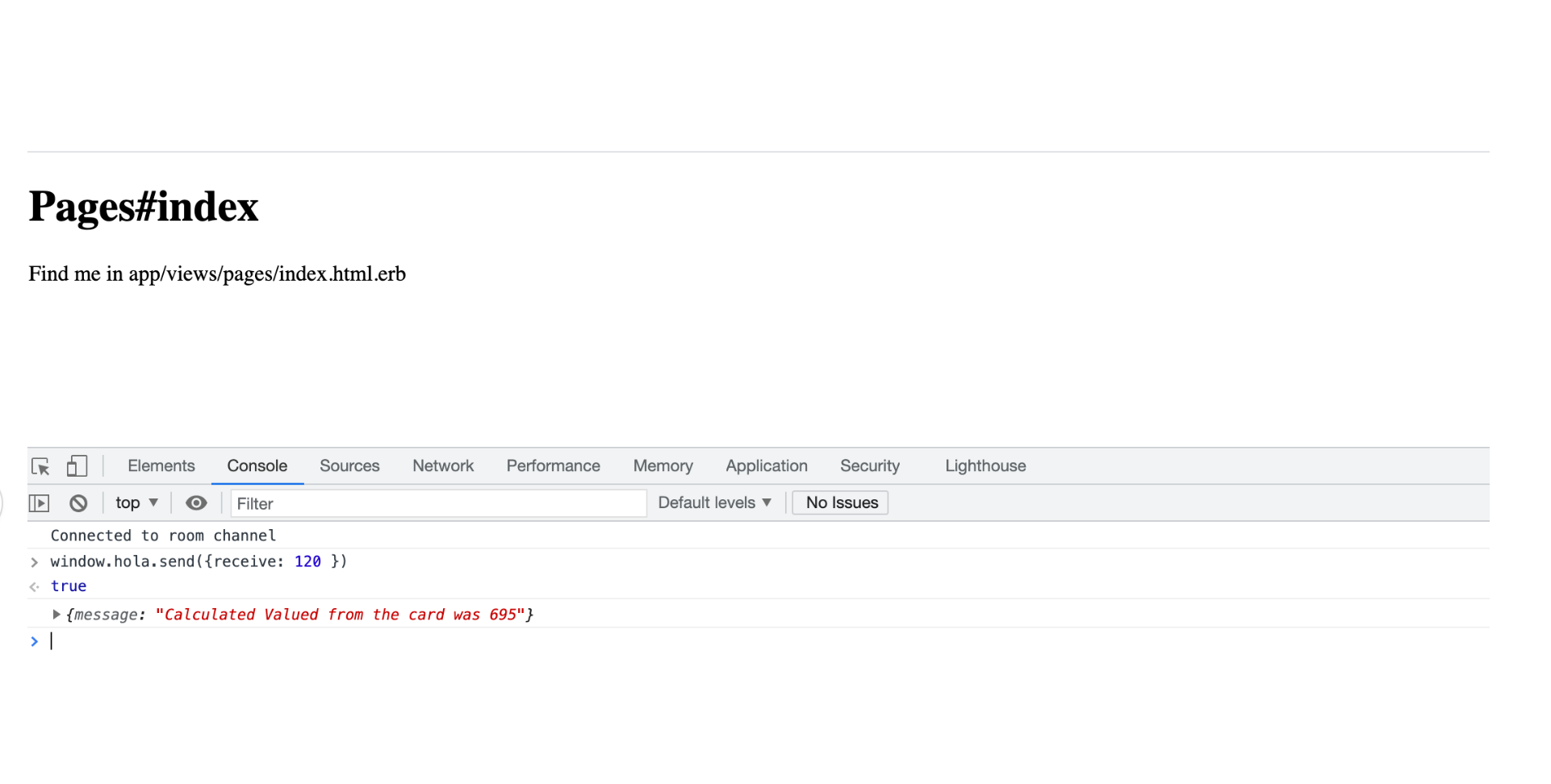
Starting from here, you can do pretty much anything: from some advanced calculations using a Cluster of Nvidia Cards with unlimited power to use a humble Jetson Nano.
And, here is a version of top for the Jetson Nano "jtop". With this, we can follow the performance of the machine.
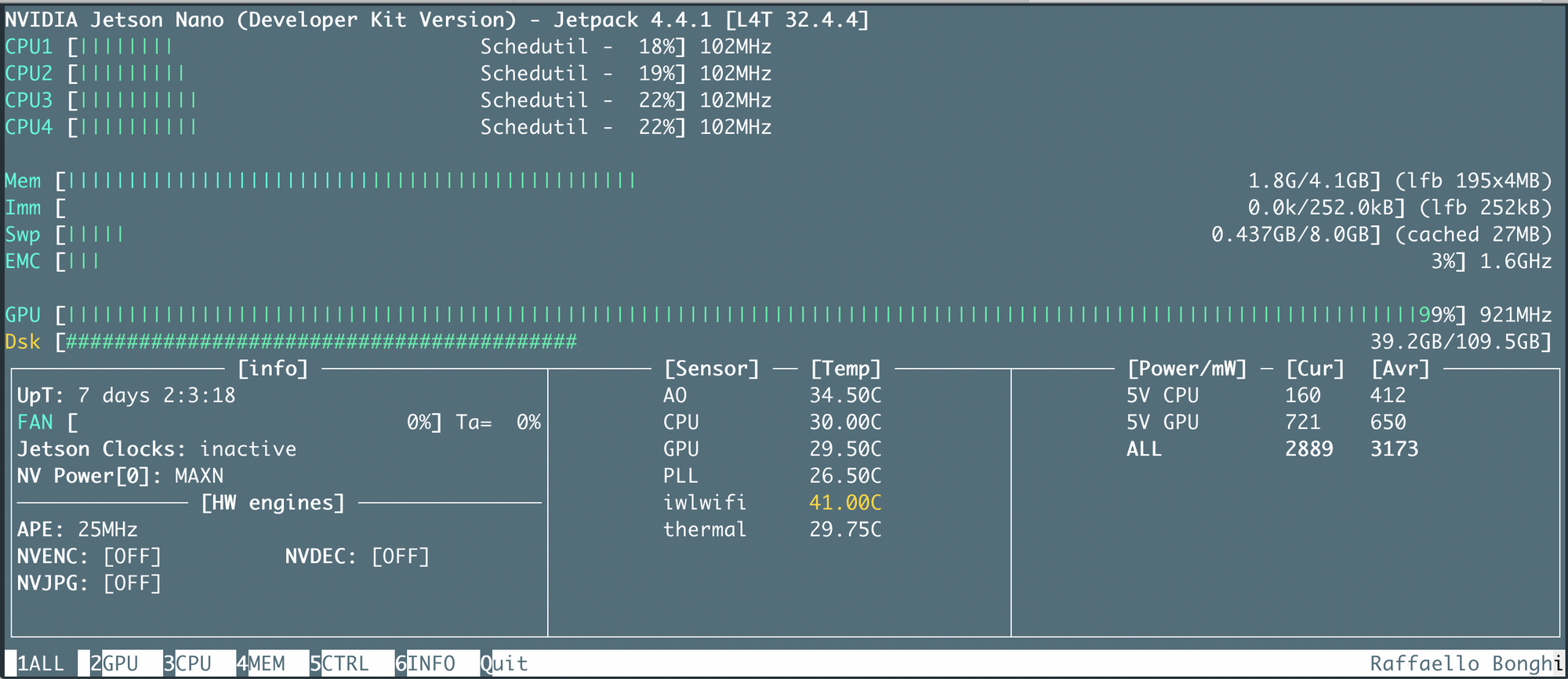
The whole point of the project is to have my Pac-Man Clone being played using a neural network that will potentially run in the card itself but, at this point, I'm far from it.
I hope this Blog will help anybody in need of massive computing power and wants to use a nice framework like Rails ;)
Until Next time Happy Coding.

View Comments